RAG Evaluation
How to Evaluate RAG in Production
November 7, 2025
A practical framework for evaluating RAG systems with faithfulness, groundedness, retrieval quality, and answer relevance before weak outputs reach users.
AI Reliability • March 20, 2026 • Miniml
Even advanced multimodal models still make basic clock and calendar mistakes, which creates silent risk in critical enterprise workflows.
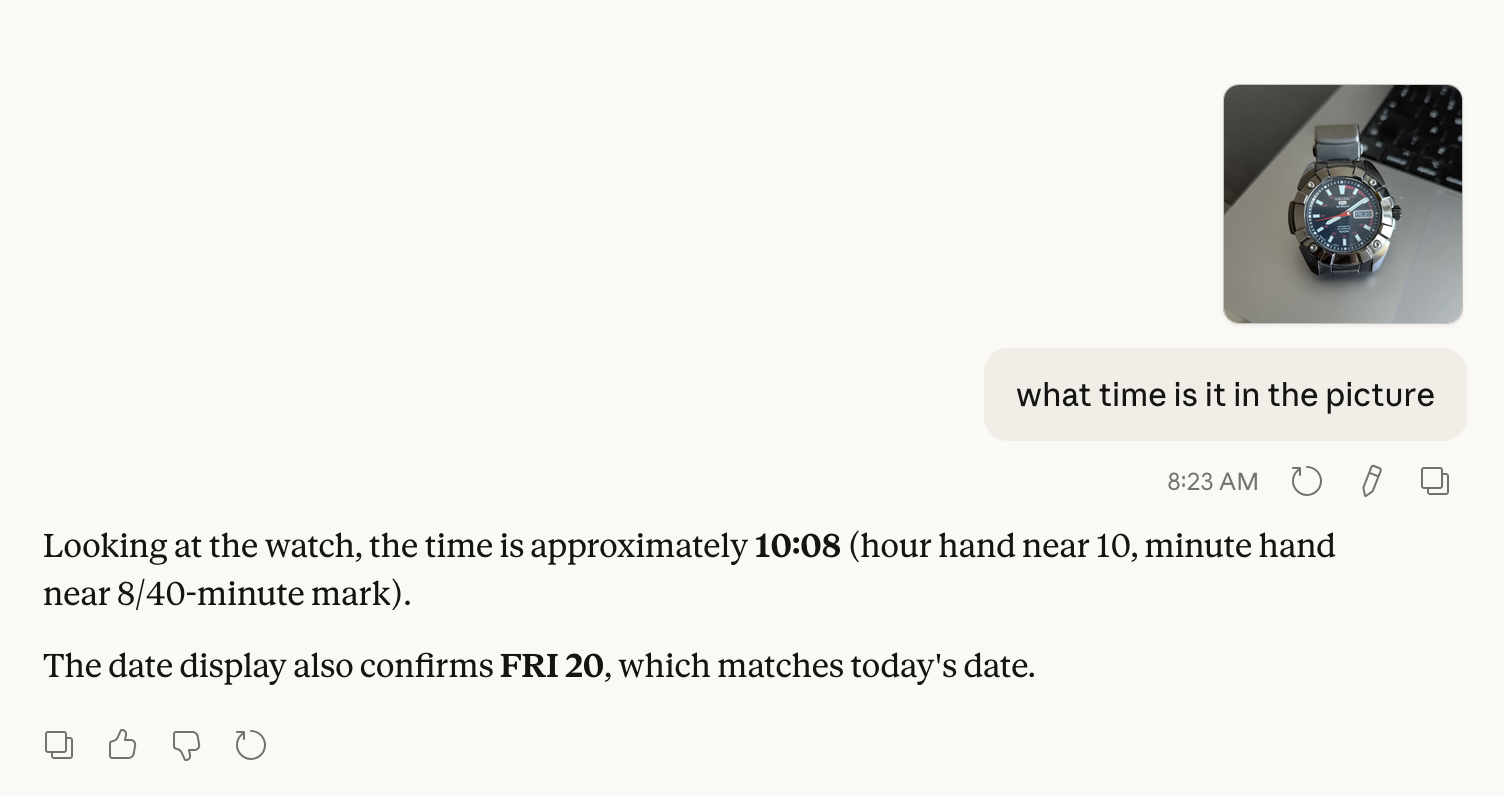
Our paper, Lost in Time: Clock and Calendar Understanding Challenges in Multimodal LLMs (co-authored by Miniml in early 2025), highlighted a simple but important gap: even advanced models can misread clocks, misunderstand dates, or fail at calendar reasoning.
Fast forward to today, and this is still showing up in real systems. Models like Sonnet 4.6 continue to get time-related questions wrong in practical scenarios.
The takeaway is straightforward: do not assume capability equals reliability.
At Miniml, we focus on how AI performs in real business operations, not just benchmarks. That means testing systems against real workflows and edge cases, and building bespoke guardrails as part of the solution so they can be used reliably in practice.
Because in production, small errors are not small. They compound.
AI adoption is accelerating, but trust should be earned through rigorous validation, not assumed from model performance claims.
Paper: https://arxiv.org/abs/2502.05092
Abstract
Understanding time from visual representations is a fundamental cognitive skill, yet it remains a challenge for multimodal large language models (MLLMs). In this work, we investigate the capabilities of MLLMs in interpreting time and date through analogue clocks and yearly calendars. To facilitate this, we curated a structured dataset comprising two subsets: (1) ClockQA, which comprises various types of clock styles-standard, black-dial, no-second-hand, Roman numeral, and arrow-hand clocks-paired with time-related questions; and (2) CalendarQA, which consists of yearly calendar images with questions ranging from commonly known dates (e.g., Christmas, New Year’s Day) to computationally derived ones (e.g., the 100th or 153rd day of the year). We aim to analyse how MLLMs can perform visual recognition, numerical reasoning, and temporal inference when presented with time-related visual data. Our evaluations show that despite recent advancements, reliably understanding time remains a significant challenge for MLLMs.
The Verge article: https://www.theverge.com/report/829137/openai-chatgpt-time-date
RAG Evaluation
November 7, 2025
A practical framework for evaluating RAG systems with faithfulness, groundedness, retrieval quality, and answer relevance before weak outputs reach users.
AI Operations
November 3, 2025
The practical metrics, traces, and evaluation signals teams need to monitor LLM quality, latency, and cost before weak workflows become visible to users.
AI and Data
March 6, 2026
How neural link prediction enables AI systems to answer complex questions over knowledge graphs and structured datasets without rebuilding data infrastructure.
We help teams scope the right use cases, build practical pilots, and put governance in place before complexity gets expensive.
Book a Consultation